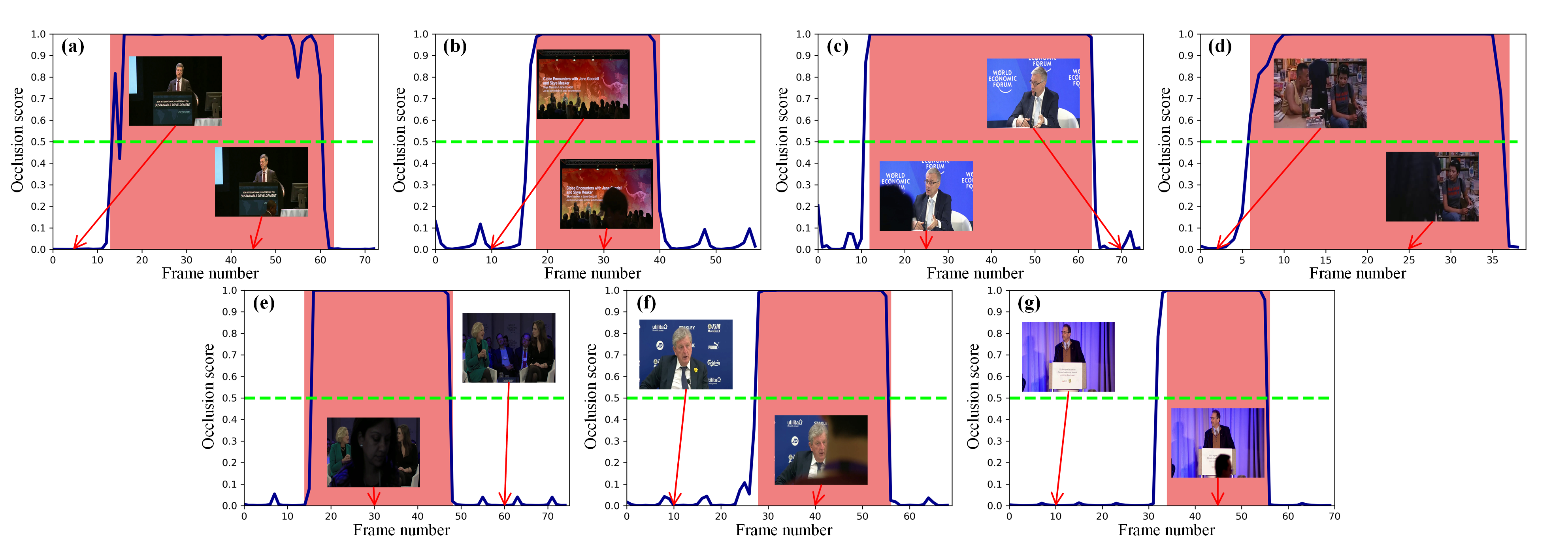
Videos have become the new preference comparing with images in recent years. However, during the recording of videos, the cameras are inevitably occluded by some objects or persons that pass through the cameras, which would highly increase the workload of video editors for searching out such occlusions. In this paper, for releasing the burden of video editors, a frame-level video occlusion detection method is proposed, which is a fundamental component of automatic video editing. The proposed method enhances the extraction of spatial-temporal information based on C3D yet only using around half amount of parameters, with an occlusion correction algorithm for correcting the prediction results. In addition, a novel loss function is proposed to better extract the characterization of occlusion and improve the detection performance. For performance evaluation, this paper builds a new large scale dataset, containing 1,000 video segments from seven different real-world scenarios. All occlusions in video segments are annotated frame by frame with bounding-boxes so that the dataset could be utilized in both frame-level occlusion detection and precise occlusion location. The experimental results illustrate that the proposed method could achieve good performance on video occlusion detection compared with the state-of-the-art approaches. To the best of our knowledge, this is the first study which focuses on occlusion detection for automatic video editing.